网络技术如何能够帮助解决大数据问题?

05-15, 2016
1 What is big data? 什么是大数据?
什么是大数据?大数据定义为“超出常用软件工具来捕获,管理能力和处理数据量的数据集,在可容忍的时间”[ 13 ]。大数据有多大?据估计,在2020年在这个世界上,总的数据量将达到35ZB(1zb = 270B),包括个人资料75%(主要是图片、视频和音乐),远远超过打印数据在整个人类历史的总量(200PB)。“大小”,大数据是指为了不断提高。大数据不仅指的是一个“大”的数据集,但也有时指的是一个“复杂的”结构的数据集[ 4 ]。传统的数据处理方法不再有效,大数据科学家开发了先进的统计方法,如保险[ 11 ]的预测分析,从数据集显示有意义的信息和辅助决策[ 3 ]。在这个意义上,科学大数据是信息处理[ 10 ]的一部分,它的定义是“变化(处理)的信息以任何方式检测由一个观察者”。置信决策从大数据中提取的巨大的洞察力将一等操作和降低风险的效率。What is big data? Big data is dened as "data sets with volumes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time" [13]. How bit is the big data? It is estimated that in 2020, the total data amount in this world will reach 35ZB (1ZB = 270B), including 75% of personal data (mostly pictures, videos and music), far more than the total amount of printed data in the entire human history (200PB).The "size" that big data is referring to is constantly increasing. Big data is also complex and require new approaches to extract insight from it. Big data is not only referring to a "large” data set but also sometimes referring to a data set with a "complex” structure [4]. As traditional data processing methods are no longer ecient, big data scientists developed advanced statistical methods, such as the predictive analytics in insurance [11], to reveal meaningful information from the data set and to assist decision making [3]. In this sense, big data science is part of information processing [10], which is dened as "the change (processing) of information in any manner detectable by an observer". The condence in decision making developed from tremendous insights extracted from the big data will a ect the eciency in operation and risk reduction.
Where does big data emerge?
Big data is generated in almost everyeld such as science, art, business, education, environment, government, and history, to "spot business trends, prevent diseases, combat crime and so on” [17]. For example, in Astronomy
eld, the Sloan Digital Sky Survey collected more than 140 terabytes of imaging data from its telescope in New Mexico since 2000 to cover 35% of the sky [12]. In government, Big Data Research and Development Initiative was established in 2012 to address important issues [8]. In retail business #p#分页标题#e#
eld, Wal-Mart feeds databases more than 2.5 petabytes [17]. In social-networking
eld, Facebook is fed by 40 billion photos [2]. Why is the big data emerging rapidly everywhere? One main reason of rapid growing data sets is the cheap collection and storage of data than ever. The capacity to store data per-capita approximately doubles every 40 months since the 1980s [7].
What are the main characteristics of big data?
There are three traditionally recognized characteristics of big data: increasingly high volume, high velocity (input and output speed of data) and high variety (type of data) [9]. These three characteristics are known as the \3Vs” model, widely used as an industrial description of big data [1]. Nowadays, two more Vs are introduced as variability (inconsistencies in data) and veracity (quality of data) [22].
1.1 Top eight trends of big data in 2016
At the end of 2015, Tableau has released the top eight trends in big data for 2016 as the following [19]. 1
. \1. The NoSQL Takeover” NoSQL databases store and retrieve data in a non-relational way, other than tabular relations used in relational databases [18]. With a much simpler structure, NoSQL databases are often more exible than traditional relational databases [16]. . \2. Apache Spark lights up big data” Apache Spark is a fast and general engine for large-scale data processing with lightning-fast cluster computing. It is now the largest big data open source computing framework in the world [19]. Spark provides an interface for programming on clusters with data parallelism and fault-tolerance [14]. . \3. Hadoop projects mature” Apache Hadoop is an open source software framework for big data with the assumption that hardware failures are common and should be automatically coped with by the framework [21]. Among a recent survay of 2200 its costumers, 76% existing users will continue use it and half of the non-hadoop users will start to use hadoop [19]. . \4. Big data grows up: Hadoop adds to enterprise standards” As an example, the new Apache Sentry project on a Hadoop cluster enhances the enterprises’ security by
ne-grained, role based authorization to data [15]. . \5. Big data gets fast: Options expand to add speed to Hadoop” New technologies as Cloudera Impala, AtScale, Actian Vector and Jethro Data are combined with Hadoop to increase the data retrieving speed [19]. . \6. The number of options for preparing end users to discover all forms of data grows” Investments have been made onto time and complexity reduction on data preparation for analysis on the users’ end. . \7. MPP Data Warehouse growth heats up in the cloud” MPP stands for massively parallel processing. A data warehouse (DW) is a system that is used for reporting and data analysis. Cloud computing is an internet-based computing that shares resources and data with any other devices on demand [6]. The cloud computing allows one to dynamically scale up the amount of storage in the data warehouse [19]. . \8. The buzzwords converge” Internet of Things allows the leading cloud companies in the world to move data onto the their data analysis engines on the cloud [19]. #p#分页标题#e#
1.2 Five big data challenges/problems
Big data is faced with many challenges such as more e
cient data curation, faster data searching, faster and more accurate data transfer, economic and stable data storage, more e
cient data analysis methods (such as massive parallel computing on hundreds and thousands of servers) beyond traditional means, faster data visualization, and information privacy as half of the data online nowadays is unprotected. Among all these challenges, SAS has summarized the following top
ve challenges. . \1. meeting the need for speed” This means to
nd the relevant data quickly through the enormous volumes of data. 2
. \2. Understanding the data” This means to have a good understanding of where the data came from, who will interpret the information, and where will the insight extracted from the big data will be applied. This means to be conscious about the bias. . \3. Addressing data quality” This means that the decision making will be misled by inaccurate big data. . \4. Displaying meaningful results” When the amount of information is extremely large, such as 10 billion rows, drawing 10 billion lines together will make it di
cult to extract useful insights. In that case, methods such as clustering data will be applied to analyze the big data on a di
erent scope. . \5. Dealing with outliers” Outliers are the data points that don't follow the main trend of data. Although only 1 to 5 % of the data points are outliers, but on the big data scale, the quantity of outliers can be massive. New methods are to be developed to quickly recognize outliers and to e
ciently present the outliers.
2 Networking technology cloud computing is the big data's new home 网络技术是云计算的大数据的新家
2.1 Cloud computing and big data in general What is cloud computing and what is big data? Simply put, cloud computing means to virtualize the hardware resources and big data means to process the enormous volume of data e
ciently. As an analogy, the cloud computing is equivalent to our computers and operating systems. The cloud computing virtualize large amount of hardware resources then allocate them for use. The biggest cloud computing user is the Amazon nowadays, setting up the business standard of applications of cloud computing. The cloud computing is an internet based technology as shown in Figure 1. What is the relation between cloud computing and big data? The cloud computing focuses on storage such as physical memory and storage. The big data emphasizes on the data base, that integrates and stores the data based on the cloud computing. Now you might have heard of the word business intelligence (BI). BI is to do data modeling and data mining, based on the large data base from the big data (constructed on top of cloud computing). Therefore, big data is a tool for BI. The idea way to provide big data with computing resources and capacities is through cloud computing. How can big data benet from the exibility of cloud computing? What is good? It requires high computing power and processing capability of system to analyze the large amount of data in big data. The traditional way requires a supercomputer to handle it, however time is wasted when the computer is in idle and the computing power might be insu #p#分页标题#e#
cient when it is busy with too many tasks. Therefore, the exibility in the on-demand computing resource in cloud computing provided the big data with full computing capacity and resources. How are we using cloud computing? Please see a survey of application of cloud computing from the Ubuntu 2013 Server and Cloud Survey in Figure 2. What are the issues on security and privacy in big data clouds? What is bad? With the technological innovation generated big data and cloud computing, this era gives birth to strong demand for 3
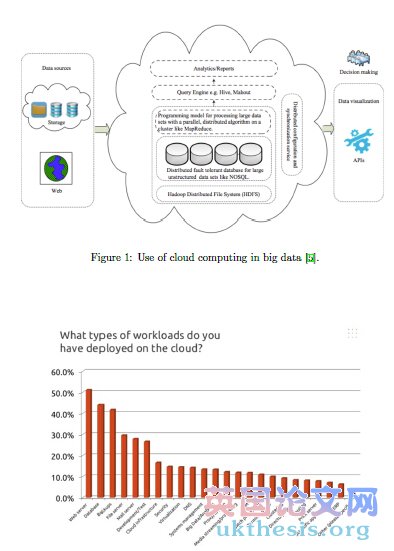
Figure 1: Use of cloud computing in big data [5]. Figure 2: How the cloud computing is used form the Ubuntu 2013 Server and Cloud Survey. 4
protection of personal privacy in all sectors of our society, that is a part of our social progress. Privacy violations in the cloud computing era of big data can happen during the data storage process. Cloud service users cannot know the exact location of data storage, therefore the users cannot e
ectively control the data collection , storage, use and share. This may be due to legal requirements in di
erent countries and cause legal con ict. This may also cause data pooling and data missing. Due to the fact that data transmission on the cloud are more open and pluralistic, traditional physical isolation cannot guarantee the safety during long distance transmission of data and electromagnetic leakage. Eavesgropping will become more prominent security threats during the data transmission. The privacy violation can also happen in the process of data processing. Cloud service providers can deploy a large number of virtual technology, failure vulnerability and encryption infrastructure, that may generate new security risks. Large-scale data processing needs complete access control and identity management to prevent unauthorized access to data, but the cloud service's dynamically shared resource model will increase the di
culty of this management. Account hijacking, attacks, disguise identity, and lost authentication failure keys may all threaten the security of user data. Therefore, in the era of big data in the cloud, we want to strengthen the protection of personal privacy.
2.2 Amazon Web Services (AWS) as an example of big data in the cloud The following case illustrates the value and contribution of the Amazon AWS to the large data processing and application. AWS helps the world's largest stock markets process global transactions. As one of the world's largest stock markets, the Nasdaq uses the Amazon AWS big data platform every day for data collection, processing and analysis of billions of records. Since Amazon AWS was established in 2006, the Nasdaq became its loyal users. In October 2014, the Nasdaq has reached a peak of 14 billion data the day of data processing has reached a peak of 14 billion in a day on AWS. In addition, the Nasdaq also use the Amazon S3 and Amazon EMR to achieve independent data computing and hosting. Amazon S3 has a nearly perfect scalability of 99.99999%. You do not need to spend too much money to make the data go across multiple regions and go between di#p#分页标题#e#
erent data centers freely. Also, Nasdaq's usage in the Amazon EMR makes deploying and managing Hadoop cluster very simple. According to their business needs, they have the freedom to control the growth of clusters or contraction, or even turn it off during the holiday weekend. Amazon AWS gave endless possibilities to Nasdaq on the big data handling and maintenance.
3 Summary 概要
Under the theme of \how networking technologies can contribute to solving the big data problems", we
rst introduced the concept of big data. Then we discussed the key challenges in big data. We introduced a popular concept of cloud computing as one of the technologies that helps us solve the big data problems. An example of Amazon's big data cloud is also given to demonstrate how cloud computing facilitates the big data processing.
References 文献
[1] M. Beyer, Gartner Says Solving 'Big Data’ Challenge Involves More Than Just Managing Volumes of Data (2011), Gartner.
[2] Facebook.com, Scaling Facebook to 500 Million Users and Beyond” (2013).
[3] C. French, Data Processing and Information Technology (10th ed.), Thomson (1996), p. 2.
[4] I.A.T. Hashem, I. Yaqoob, N. Badrul Anuar, S. Mokhtar, A. Gani, S.U. Khan, "big data” on cloud computing: Review and open research issues". Information Systems 47 (2015), p. 98{115.
[5] I.A.T. Hashem, I. Yaqoob, N.B. Anuar,S. Mokhtar, A. Gani, S.U. Khan, The rise of \big data? on cloud computing: Review and open research issues, Information Systems 47 (2015), p. 98{115.
[6] Q. Hassan, Demystifying Cloud Computing, The Journal of Defense Software Engineering (CrossTalk) (2011), p. 16{21.
[7] M. Hilbert, P. Lopez, The World's Technological Capacity to Store, Communicate, and Compute Information, Science 332 (6025), (2011), pp. 60{65.
[8] T. Kalil, Big Data is a Big Deal, White House (2012). R
[9] D. Laney, 3D Data Management: Controlling Data Volume, Velocity and Variety (2001), Gartner.
[10] D. McGonigle, K. Mastrian, introduction to information, information science, and information systems, 2 ed. (2011), p. 22.
[11] C. Nyce, Predictive Analytics White Paper, American Institute for Chartered Property Casualty Underwriters/Insurance Institute of America (2007), p. 1.
[12] M. Sako, et al., The Data Release of the Sloan Digital Sky Survey-II Supernova Survey (2014), ArXiv e-prints.
[13] C. Snijders,U. Matzat, U.-D. Reips, `Big Data': Big gaps of knowledge in the
eld of Internet, International Journal of Internet Science 7 (2012), 1{5.
[14] M. Zaharia, M. Chowdhury, M.-J. Franklin, S. Shenker, I. Stoica, Spark: Cluster Computing with Working Sets, USENIX Workshop on Hot Topics in Cloud Computing (HotCloud) (2010). #p#分页标题#e#
[15] Cloudera Brings Role-Based Security To Hadoop, Information Week (2013).
[16] Customers like SimpleDB?s table interface and its exible data model.
[17] Data, data everywhere, The Economist (2010).
[18] NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable.
[19] Top 8 trends for big data in 2016, Information Age (2015).
[20] Ubuntu 2013 Server and Cloud Survey, Ubuntu Server (2013).
[21] Welcome to Apache Hadoop (2015).
[22] What is Big Data?, Villanova University.